
When building REST APIs, pagination is a crucial feature for handling large datasets efficiently.
In this post, we’ll explore two different approaches to implement pagination with caching in a C# Minimal API.
Obviously, we will use the same project used in all Minimal APIs’ posts.
Before to see the two implementations, we have to modify the method LoadDefaultValuesDB, in order to have more items to use in our APIs:
public async Task LoadDefaultValuesDB()
{
List<Dog> lstDogs = new List<Dog>();
for (int i = 1; i <= 1000; i++)
{
await _dataContext.Dogs.AddAsync(new Dog { Id = i, Name = $"Name_{i}", Breed = $"Breed_{i}", Color = $"Color_{i}" });
}
await _dataContext.SaveChangesAsync();
}
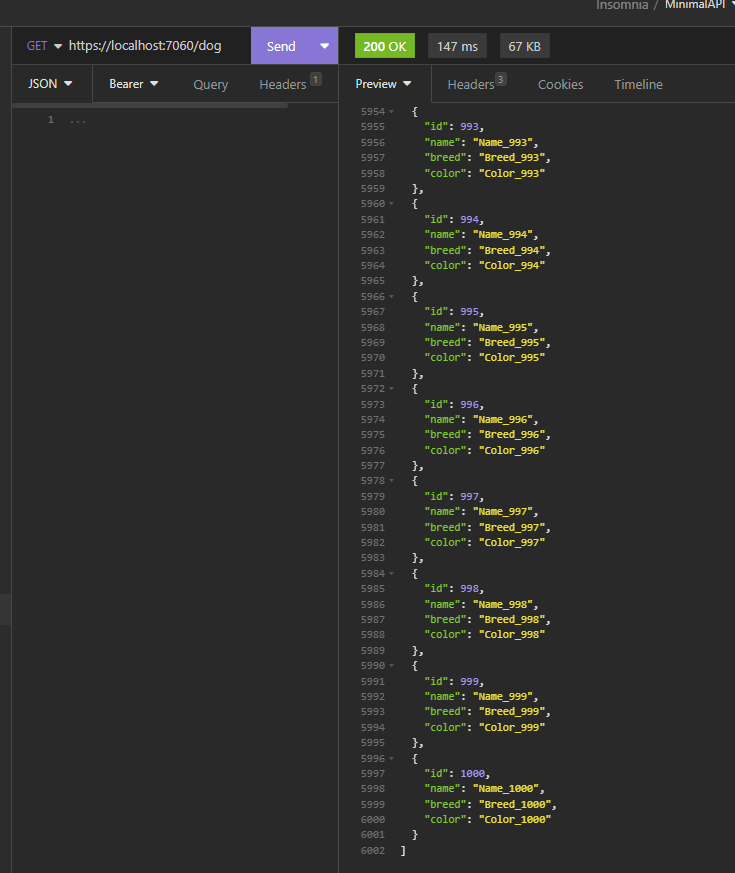
Now, if we run the APIs and we call the endpoint “/dog”, the following will be the result:
Finally, we have to modify the method GetAllDogs to manage the page and pagesize parameters:
public async Task<List<Dog>> GetAllDogs(int page, int pageSize)
{
_logger.LogInformation("BLL - Retrieving all dogs");
var query = _dataContext.Dogs.AsNoTracking();
if (! await query.AnyAsync())
{
await LoadDefaultValuesDB();
// Refresh the query after loading default values
query = _dataContext.Dogs.AsNoTracking();
}
List<Dog> lstDogs = null;
if (page == 0 && pageSize == 0)
{
lstDogs = await query.ToListAsync();
}
else
{
lstDogs = await query.Skip((page - 1) * pageSize).Take(pageSize).ToListAsync();
}
return lstDogs;
}
Approach 1: Cache Pages Individually
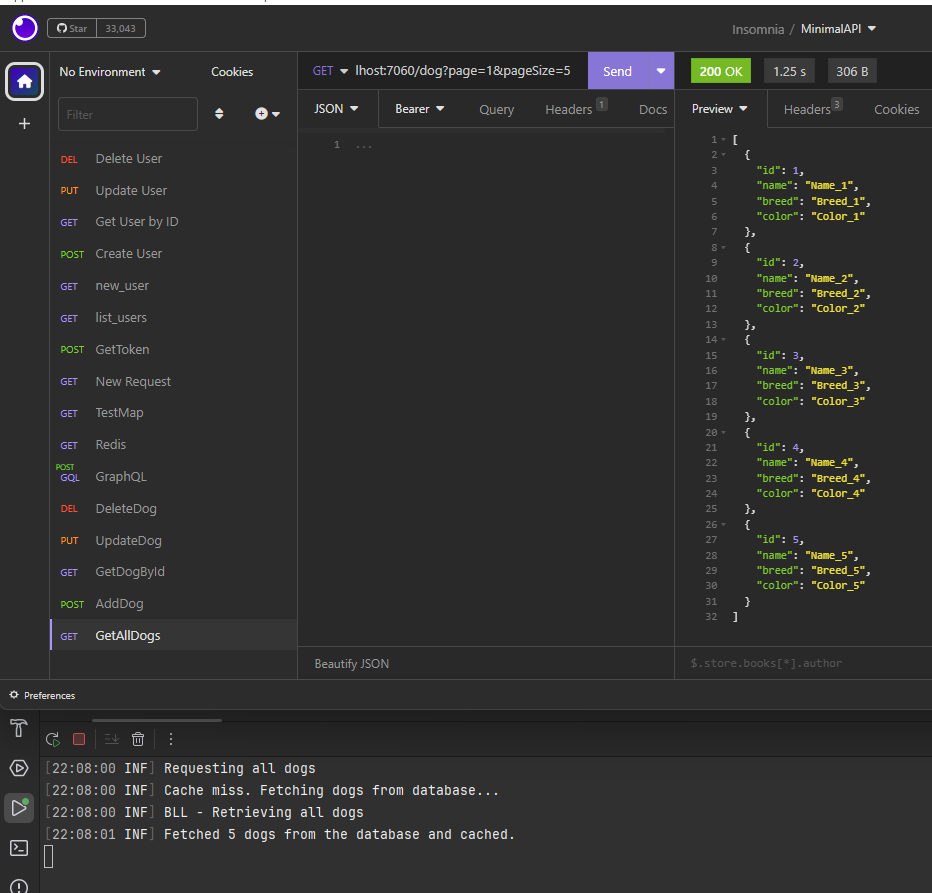
In the first approach, we cache each page of data separately. This means when a user requests a page, the API checks if that specific page is already in the cache. If it is not, the API fetches the data from the database, caches it, and then returns it to the user. This approach is beneficial when dealing with very large datasets where caching the entire dataset would be impractical.
app.MapGet("/dog", async (IDogCommands commands, ILogger<Program> loggerInput, IMemoryCache cache, int? page, int? pageSize) =>
{
page ??= 1;
pageSize ??= 10;
string cacheKey = $"dogsList_page_{page.Value}_size_{pageSize.Value}";
List<Dog> dogs = null;
// Log the beginning of the request to get all dogs
loggerInput.LogInformation("Requesting all dogs");
// Try to retrieve the cached list of dogs
if (!cache.TryGetValue(cacheKey, out dogs))
{
loggerInput.LogInformation("Cache miss. Fetching dogs from database...");
// Execute the GetAllDogs command to retrieve all dogs
dogs = await commands.GetAllDogs(page.Value, pageSize.Value);
// Check if the result is null or empty
if (dogs == null || !dogs.Any())
{
// Log a warning indicating that no dogs were found
loggerInput.LogWarning("No dogs found");
// Return a NotFound result to indicate that no dogs were found
return Results.NotFound();
}
// Set cache with a relative expiration time of 5 minutes
var cacheEntryOptions = new MemoryCacheEntryOptions()
.SetSlidingExpiration(TimeSpan.FromMinutes(2));
cache.Set(cacheKey, dogs, cacheEntryOptions);
loggerInput.LogInformation($"Fetched {dogs.Count} dogs from the database and cached.");
}
else
{
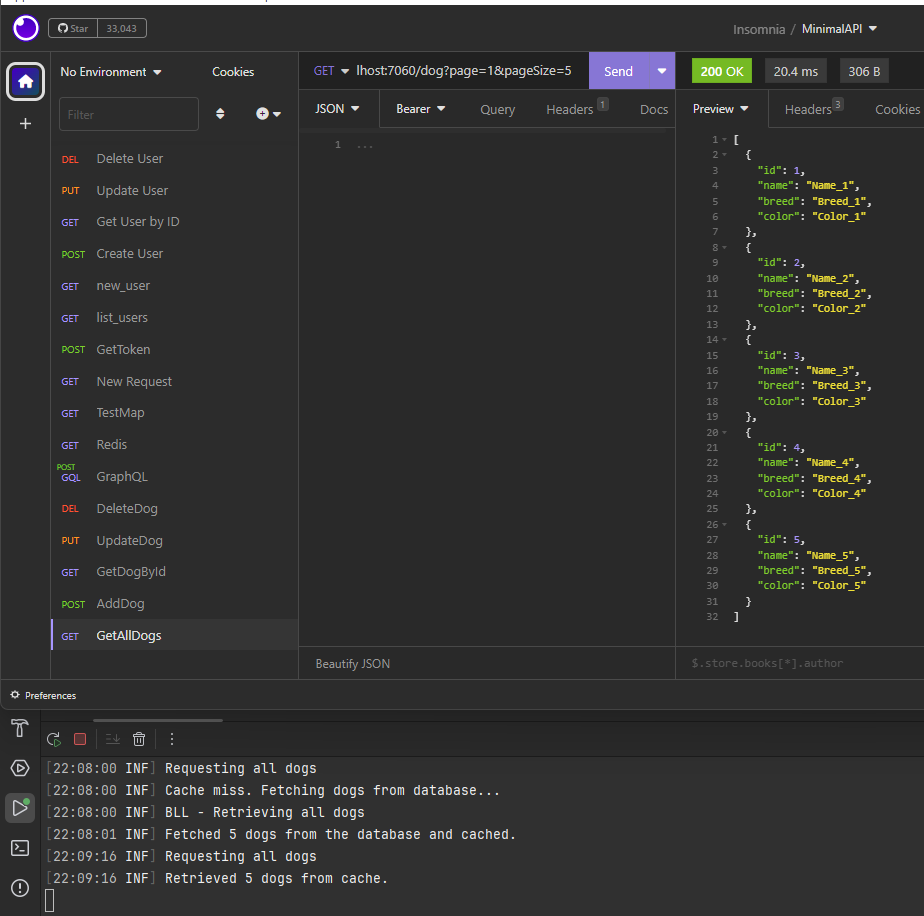
loggerInput.LogInformation($"Retrieved {dogs.Count} dogs from cache.");
}
// Return an Ok result with the list of retrieved dogs
return Results.Ok(dogs);
}).RequireAuthorization();
If we run the application, the following will be the result:
[BENEFIT]
Reduces memory usage as only required pages are cached.
Potentially fresher data as each page is cached separately.
[DRAWBACKS]
Higher database load if frequently accessed pages are not in cache.
More complex cache management, especially with cache invalidation.
Approach 2: Cache the Entire Dataset
The second approach involves caching the entire dataset at once. When a request comes in, the data is retrieved from the cache, and pagination is applied in the code to return the appropriate slice of data. This approach is suitable for datasets that are not excessively large and do not change frequently.
app.MapGet("/dog", async (IDogCommands commands, ILogger<Program> loggerInput, IMemoryCache cache, int? page, int? pageSize) =>
{
page ??= 1;
pageSize ??= 10;
string cacheKey = $"allDogsList";
List<Dog> dogs = null;
// Log the beginning of the request to get all dogs
loggerInput.LogInformation("Requesting all dogs");
// Try to retrieve the cached list of dogs
if (!cache.TryGetValue(cacheKey, out dogs))
{
loggerInput.LogInformation("Cache miss. Fetching dogs from database...");
// Execute the GetAllDogs command to retrieve all dogs
dogs = await commands.GetAllDogs(0, 0);
// Check if the result is null or empty
if (dogs == null || !dogs.Any())
{
// Log a warning indicating that no dogs were found
loggerInput.LogWarning("No dogs found");
// Return a NotFound result to indicate that no dogs were found
return Results.NotFound();
}
// Set cache with a relative expiration time of 5 minutes
var cacheEntryOptions = new MemoryCacheEntryOptions()
.SetSlidingExpiration(TimeSpan.FromMinutes(2));
cache.Set(cacheKey, dogs, cacheEntryOptions);
loggerInput.LogInformation($"Fetched {dogs.Count} dogs from the database and cached.");
}
else
{
loggerInput.LogInformation($"Retrieved {dogs.Count} dogs from cache.");
}
var paginatedDogs = dogs.Skip((page.Value - 1) * pageSize.Value).Take(pageSize.Value).ToList();
if (!paginatedDogs.Any())
{
loggerInput.LogWarning("No dogs found on the requested page");
return Results.NotFound();
}
// Return an Ok result with the list of retrieved dogs
return Results.Ok(paginatedDogs);
}).RequireAuthorization();
If we run the application, the following will be the result:
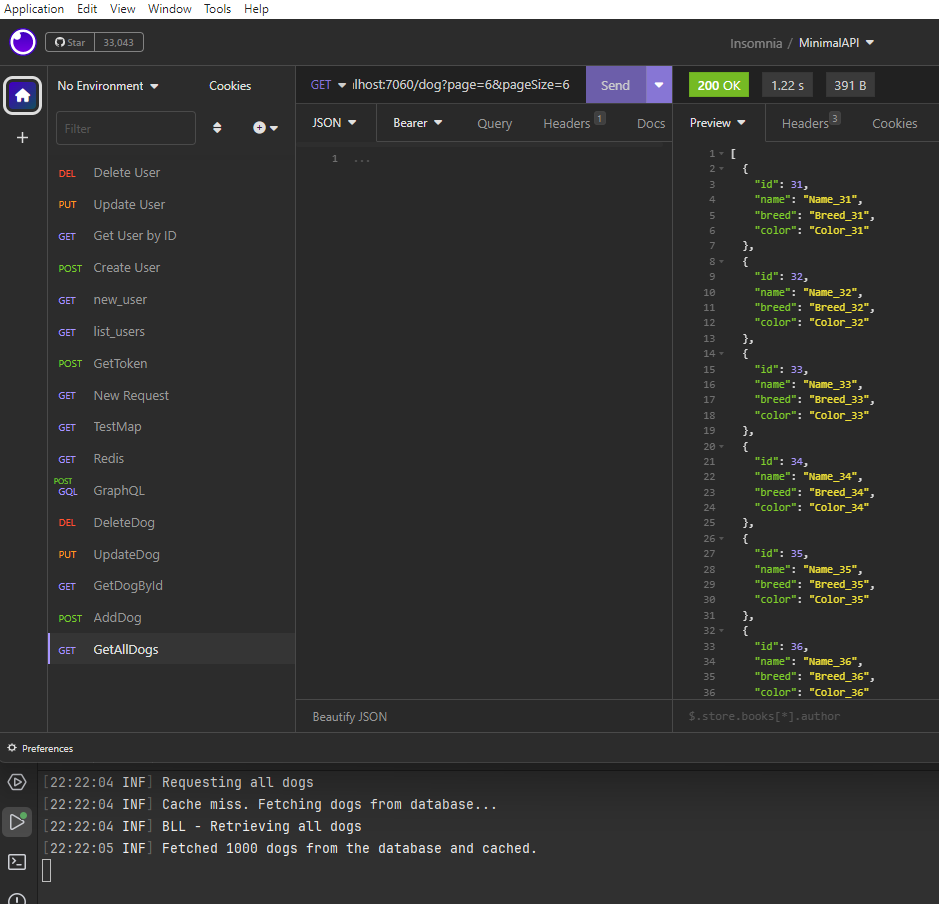
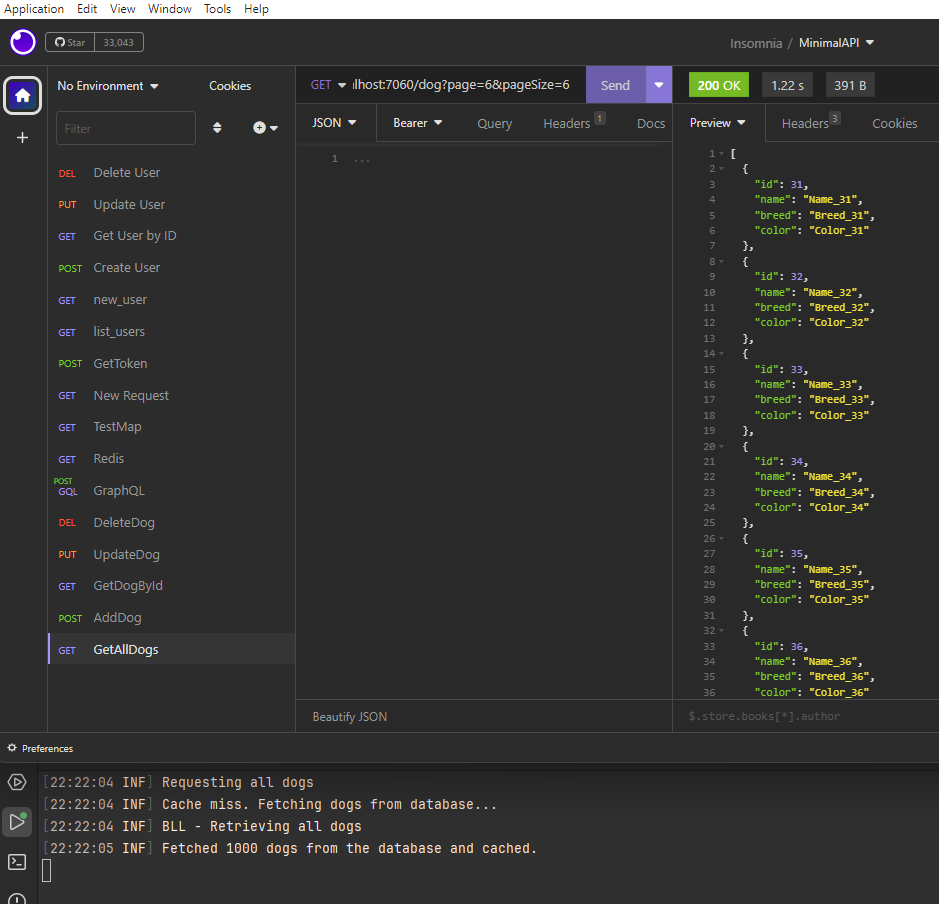
[BENEFIT]
Reduces database load significantly as the entire dataset is fetched and cached once.
Simplifies the pagination logic in the API as it just involves slicing the cached list.
[DRAWBACKS]
High memory usage if the dataset is large.
Potential for stale data unless cache invalidation strategies are effectively implemented.
Choosing between these two pagination and caching strategies depends largely on the size of our dataset and how frequently the data changes. For very large or frequently updated datasets, caching individual pages may be more appropriate. For smaller or rarely changed datasets, caching the entire dataset can reduce database load and simplify our APIs.